
Aurora DSQLにdrizzleでLambdaからmigrationしてみた
この記事は公開されてから1年以上経過しています。情報が古い可能性がありますので、ご注意ください。
製造ビジネステクノロジー部のやまたつです!
re:Invent 2024で発表されたAmazon Aurora DSQLに、Lambdaからdrizzleを使ってmigrationしてみました。
コード:
CDK が実行されたら migration する
CDKのコード: (GitHub)
import * as triggers from "aws-cdk-lib/triggers";
// 省略...
new triggers.Trigger(stack, "Trigger", {
handler: fn("Migrator", {
entry: "../lambda-node/src/handlers/migrator.ts",
timeout: cdk.Duration.minutes(1),
}),
});
function fn(id: string, props: nodejs.NodejsFunctionProps) {
return new nodejs.NodejsFunction(stack, id, {
functionName: `PlayDsql-${id}`,
...props,
// 省略...
});
}
aws-cdk-lib/triggersを使います。これによりcdk deployのタイミングでLambdaが実行されます。
実行されるLambdaの中身は../lambda-node/src/handlers/migrator.tsにあるので、そちらを見ていきます。
migrationするLanmbda関数の実装
コード: (GitHub)
import { pushSchema } from "drizzle-kit/api";
import * as tables from "../db/schema.js";
import { generateDrizzleClient } from "../utils.js";
const db = await generateDrizzleClient();
export const handler = async () => {
console.log("Running migrations...");
const start = Date.now();
// CLIコマンド`drizle-kit push`と同等の処理を行う
const { hasDataLoss, warnings, statementsToExecute, apply } =
await pushSchema(tables, db);
// hasDataLoss: `apply()`によってデータが失われるかどうか
// warnings: `apply()`を実行する上での警告事項
// statementsToExecute: `apply()`によって実行されるSQL文
console.log({ hasDataLoss, warnings, statementsToExecute });
// migrationの実行
await apply();
const end = Date.now();
console.log(`Migration end: ${end - start}ms`);
};
ドキュメントには特に記載はありませんが、drizzle-kitはdrizzle-kit/apiを公開してて、これを使うとtypescriptのコードからdrizzle-kitコマンドの一部の機能が使えます。
実行結果
CDKを実行してLambdaのログを確認してみました。
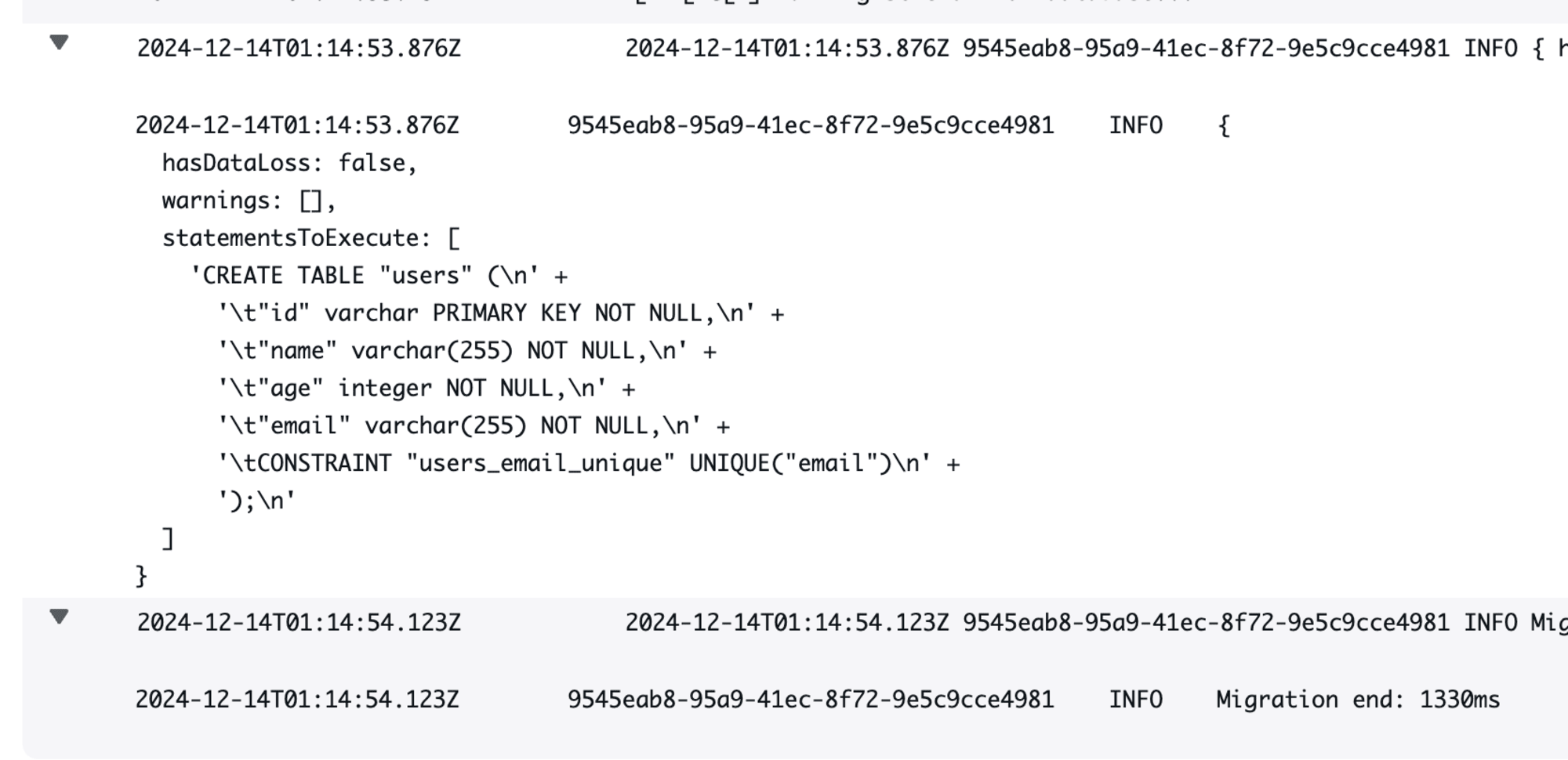
無事にmigrationできているようです。
簡単な道ではなかった。。。
今回のマイグレーションでは当初以下のようなスキーマ定義を使おうとしていました。
export const usersTable = pgTable(
"users",
{
id: integer().primaryKey().generatedAlwaysAsIdentity(),
name: varchar({ length: 255 }).notNull(),
age: integer().notNull(),
email: varchar({ length: 255 }).notNull().unique(),
}
);
しかし、DSQLに対してマイグレーションするためには、最終的には以下のような定義が必要になりました。
export const usersTable = pgTable(
"users",
{
id: varchar().primaryKey().$default(() => randomUUID()),
name: varchar({ length: 255 }).notNull(),
age: integer().notNull(),
email: varchar({ length: 255 }).notNull(),
},
(table) => [
uniqueIndex("users_email_unique").using(
"btree_index",
table.email.asc().nullsLast().op("text_ops"),
),
uniqueIndex("users_pkey").using(
"btree_index",
table.id.asc().nullsLast().op("text_ops"),
table.name.asc().nullsLast().op("text_ops"),
table.age.asc().nullsLast().op("text_ops"),
table.email.asc().nullsLast().op("text_ops"),
),
unique("users_email_unique").on(table.email),
],
);
なぜこうなったのか、順を追って見ていきます。
IDENTITY列が使えない
元々実行していた以下の定義は内部的にはIDENTITY列を使います。
.generatedAlwaysAsIdentity()
公式ドキュメントのUnsupported PostgreSQL featuresにも記載されていないのですが、DSQLではIDENTITY列を使おうとすると以下のエラーが発生します。
IDENTITY constraint is not supported
DSQLの公式ドキュメントの例では主キーにはUUIDを用いているのでそのように変更しました
id: varchar().primaryKey().$default(() => randomUUID()),
マイグレーションするたびにスキーマに差分が出る
マイグレーションするたびに作成したIndexを削除しようとする挙動がありました。
調査した結果、DSQLに以下の2つの特徴に起因していることがわかりました。
- インデックス作成クエリの解釈が一部異なる
- 一部のシステムテーブルが使えない
1. インデックス作成クエリの解釈が一部異なる
varcharを用いて主キーを作成する場合、drizzleは以下のテーブル作成クエリを発行します。
CREATE TABLE "users" (
"id" varchar PRIMARY KEY NOT NULL,
"name" varchar(255) NOT NULL,
"age" integer NOT NULL,
"email" varchar(255) NOT NULL,
CONSTRAINT "users_email_unique" UNIQUE("email")
);
このクエリによって、通常のPostgreSQLでは以下のようなpg_indexレコードが作成されます
indnatts | indkey
----------+--------
1 | 1
1 | 4
(2 rows)
しかし、DSQLでは以下のようになります
indnatts | indkey
----------+---------
4 | 1 2 3 4
1 | 4
(2 rows)
この結果を見ると、DSQLでは単一主キーとしてテーブルを作成した場合も全てのカラムに対してインデックスを作成するように見えます。
少なくとも、pg_index内でのデータの持ち方が通常のPostgreSQL実装とは異なるようです。
この結果、drizzleに実装された「現状のスキーマを把握するための仕組み」が正しく動作せず、マイグレーションのたびに余計なインデックスを削除しようとする挙動が発生しました。
2. 一部のシステムテーブルが使えない
DSQLで使えるシステムテーブルは公式ドキュメントに説明があります。
この一部の使えないシステムテーブルにライブラリが依存している場合、機能が意図通りに動かない場合があります。
drizzleではpg_stat_user_indexesというSystem viewsに依存する作りになっているのですが、この筆者が試す限りではDSQLではこのViewが空のままなので、drizzleのマイグレーション機能が正しく動作しませんでした。
serialがサポートされていない
drizzleでは現在のDBのスキーマとの差分を検知して自動的にマイグレーションを行うpushコマンドの他に、generateとmigrateの二つのコマンドを使ったマイグレーション方式が提供されています。
generateコマンドを用いてSQLファイルを生成し、migrateコマンドを用いて生成されたSQLファイルを実行します。
この方式では「現在のDBスキーマを確認する」という挙動が不要になるため、DSQLのような特殊なPostgreSQL実装でも正しく動作する可能性が高いと筆者は考えました。
しかしDSQLではこれも動作しませんでした。
この時発生したエラーが以下のエラーです。
error: type "serial" does not exist
drizzleをはじめ多くのDBマイグレーションツールでは、実行したマイグレーションSQLファイルの管理のためのテーブルを作成します。
このテーブルにserialが使われている場合、DSQLではserialがサポートされていないためエラーが発生します。
参考:
- drizzleの該当コード
- DSQL公式ドキュメント内での言及(DjangoやSQLAlchemyの説明の中にサポートしていない旨が記載されています)
まとめ
今回はCDKのTriggerを使ってLambdaからDSQLにマイグレーションを行いました。
また、drizzleを例にして既存のPostgreSQLのエコシステムが期待通りに動作しないケースについて紹介しました。
DSQL自体のGAも待ち遠しいですが、同時に効率的な開発に足るエコシステムが整備されるていくことにも貢献していきたいですね。
以上でした。










